A live migration fails at 8%. A CSV enters redirected access an hour after a backup job completes. Neither error message tells you where to start — and in most cases, the two failures share the same underlying cluster health problem.
Hyper-V live migration failed errors are among the more deceptive cluster failures: the error message points at authentication or network, the real cause is usually a vSwitch name or CSV state. This guide covers the diagnostic path for both — live migration failures, CSV redirected access, quorum loss, and cluster node isolation — ordered by how operators actually encounter them, not by how the documentation is organized.
Hyper-V live migration failed with no clear error code is a common starting point. The sections below follow that diagnostic chain from cluster health triage through recovery, including the failure scenarios that take the most time to diagnose because they look like something else.
- Run
Get-ClusterSharedVolumefirst — if any CSV showsRedirectedAccess, start with the CSV section before touching live migration settings - Hyper-V live migration failing at under 10% is almost always a vSwitch name mismatch — case-sensitive, must match exactly on every node
- Event ID 5120 is a storage path error; Event ID 5125 is a filter driver problem — different causes, different fixes
Start-ClusterNode -FixQuorumis destructive if the failed node is still powered on — confirm power state via IPMI before running- Antivirus exclusions on clustered Hyper-V must use Volume GUID paths, not
C:\ClusterStoragereparse point paths - Two-node clusters without a witness lose quorum every time one node reboots — add a cloud witness before production, not after the first incident
Cluster Health Triage — Start Here
Before chasing individual errors, run a baseline state check. This takes 60 seconds and eliminates half the wrong diagnostic paths — including the paths that make a hyper-v live migration failed error look like an authentication problem when it’s actually a CSV state problem.
Get-Cluster
Get-ClusterNode
Get-ClusterSharedVolume
Get-ClusterResource | Select Name, State, OwnerNodeHealthy cluster output:
# Healthy
Get-ClusterNode
Name State
---- -----
HV01 Up
HV02 Up
Get-ClusterSharedVolume
Name State Node
---- ----- ----
Cluster Disk 1 Online HV01
Cluster Disk 2 Online HV02Broken cluster output — what you’re looking for:
# Degraded / broken
Get-ClusterSharedVolume
Name State Node
---- ----- ----
Cluster Disk 1 RedirectedAccess HV01
Cluster Disk 2 Offline ---
Get-ClusterNode
Name State
---- -----
HV01 Up
HV02 IsolatedWhat each resource state means:
| Resource state | What it means |
|---|---|
| Online | Healthy |
| Offline | Failed or manually taken offline |
| Pending | Transitioning — wait or investigate |
| Failed | Resource hit its failure threshold |
| RedirectedAccess | CSV is online but all I/O is routing through another node |
| Isolated | Node lost communication with the cluster |
RedirectedAccess is not a failure state — it’s a degraded state. VMs continue running, but storage I/O goes over the cluster network through another node instead of directly through the local storage path. Performance degrades significantly and the underlying cause stays hidden until you look for it.
Hyper-V Live Migration Failed — Diagnostic Workflow
Where It Fails Tells You Why
The progress percentage at which a hyper-v live migration fails is a diagnostic signal, not just a frustrating number. Each phase of migration maps to a specific subsystem. Failures in that phase point to a specific category of problem.
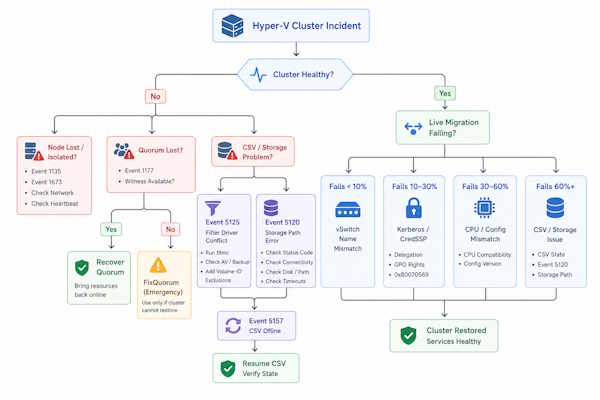
This is an investigation priority order based on where each failure type manifests in the migration sequence. Not a statistical ranking.
Pre-Migration Validation Checklist
Most hyper-v live migration failed errors are predictable. Before migrating a VM in a cluster where migrations haven’t been tested recently:
- TCP port 6600 open between all nodes (live migration traffic)
- Kerberos constrained delegation configured —
cifs+Microsoft Virtual System Migration Service - vSwitch names identical on source and destination (case-sensitive)
- CPU families compatible, or
CompatibilityForMigrationEnabledset to$true - VM config version supported on destination host
- Destination node has enough free memory for the VM’s assigned RAM
- No active or orphaned checkpoints on the VM being migrated
- No stuck migrations from a previous attempt (
Get-ClusterGroup— check for stale entries)
Hyper-V Live Migration Failed at Under 10% — vSwitch Name Mismatch
According to Microsoft’s live migration documentation, if a VM is connected to a virtual switch that doesn’t exist on the destination node, live migration fails at under 10% of completion. This is the single most common hyper-v live migration failed scenario in production clusters.
vSwitch names are case-sensitive and must be identical across all nodes. A switch named External-Production on HV01 and External-production on HV02 will cause every migration from HV01 to HV02 to fail at the same progress point.
For context on virtual switch design and naming standards, see Hyper-V Networking: Virtual Switches, VLANs, and SET Explained.
# Run on every node and compare output
Get-VMSwitch | Select Name, SwitchType
# Healthy — names match across nodes
Name SwitchType
---- ----------
External-Production External
Management Internal
# Broken — names differ
# HV01: "External-Production"
# HV02: "External-production" ← case mismatch — hyper-v live migration fails at <10%If names differ: rename the switch on the outlier node to match the cluster standard. VMs connected to the renamed switch update automatically.
Hyper-V Live Migration Failed — Authentication: Kerberos and CredSSP
Error 0x80070569: “The user name or password is incorrect.” This is the most common authentication error when a hyper-v live migration fails in the 10–30% range.
The error is misleading. The credentials are usually correct. The problem is delegation configuration.
Live migration requires constrained delegation on both cluster node computer accounts. Each node must be allowed to delegate to cifs (for CSV access) and Microsoft Virtual System Migration Service. Check delegation in Active Directory Users and Computers: computer account → Delegation tab. Both services must appear in the allowed delegation list for every other node in the cluster.
The same 0x80070569 error appears in standalone Hyper-V VM startup failures — the root cause in clustering is the same. See Hyper-V VM Won’t Start: Fix Every “Failed to Start” Error for the standalone diagnostic path.
The “Create symbolic links” GPO trap. Hyper-V live migration failed with 0x80070569 even after constrained delegation is correctly configured. Root cause: the Create symbolic links user right in Group Policy is granted only to the Administrators group. The Hyper-V migration service account doesn’t inherit this right. Fix: add NT VIRTUAL MACHINE\Virtual Machines to the user right in the applicable GPO — Computer Configuration → Windows Settings → Security Settings → Local Policies → User Rights Assignment → Create symbolic links. This is a common miss that doesn’t appear in most delegation guides.
# Verify constrained delegation on a node
Get-ADComputer -Identity "HV01" -Properties TrustedForDelegation, msDS-AllowedToDelegateTo |
Select TrustedForDelegation, msDS-AllowedToDelegateTo
# Expected output includes:
# cifs/HV02.domain.local
# Microsoft Virtual System Migration Service/HV02.domain.localCredSSP is an alternative that bypasses Kerberos delegation requirements. In environments with functional Kerberos delegation, CredSSP is not the right path — it works, but it carries broader credential exposure risk.
CPU Compatibility and Config Version Mismatch
CPU compatibility failures appear as: “The virtual machine cannot be moved because the processor on the destination computer is not compatible.” When a hyper-v live migration failed with this message, two separate problems could be the cause.
Processor generation mismatch. Nodes with different CPU generations expose different processor features to VMs. The destination node may not support a feature the VM’s processor is currently using. See Microsoft’s processor compatibility documentation for the full list of affected feature flags.
# Enable CPU compatibility mode (shut VM down first)
Set-VMProcessor -VMName "VMName" -CompatibilityForMigrationEnabled $true
# Verify
Get-VMProcessor -VMName "VMName" | Select CompatibilityForMigrationEnabledCompatibility mode limits the VM to the common feature set across nodes. The tradeoff: VMs can’t use CPU instructions specific to the newer generation. For compute-heavy or database workloads using specific instruction sets, test the performance impact before enabling cluster-wide.
Config version mismatch. VM configuration versions increment with Windows Server versions. A VM at version 9.0 (Windows Server 2019) can’t live migrate to a host running only version 8.x.
# Check config version
Get-VM -Name "VMName" | Select Name, Version
# Upgrade (VM must be shut down — one-way operation)
Update-VMVersion -VMName "VMName"Config version upgrades are one-way. If cluster nodes are at mixed Windows Server versions, hold off on version upgrades until all nodes are at the target version.
Hyper-V Live Migration Failed — Insufficient Destination Memory (0x800705AA)
Error 0x800705AA: “Not enough storage is available to complete this operation.” When a hyper-v live migration failed with this code, it’s a memory error, not a storage error. The destination node doesn’t have enough free RAM to receive the VM.
# Check available memory on destination
Get-VMHostNumaNode -ComputerName "HV02" | Select MemoryAvailableFix options: migrate other VMs off the destination node first, or enable Dynamic Memory on the VM (allows it to land with a lower footprint and expand after migration). Dynamic Memory has caveats for latency-sensitive workloads — test before relying on it in production.
Hyper-V Live Migration Failed — Stuck Migration and WinRM Issues
A hyper-v live migration stuck at a fixed percentage for more than a few minutes is usually WinRM connectivity or network saturation, not a Hyper-V configuration problem.
- Cancel the stuck migration:
Stop-VMJob -VM "VMName" - Verify WinRM connectivity between nodes:
Test-WSMan -ComputerName "HV02" - Test live migration port directly:
Test-NetConnection -ComputerName "HV02" -Port 6600 - Check whether another migration is already running:
Get-VMJob | Where-Object { $_.JobType -eq "MigrateVirtualMachine" } - Review cluster network bandwidth utilization — live migration competes with CSV I/O on the same network if a dedicated live migration network isn’t configured
CSV — Redirected Access Mode
What Redirected Access Is and Why It Matters
Cluster Shared Volumes normally let each node access storage directly through a local path. When a node enters redirected access, it loses that direct path and routes all storage I/O through another node over the cluster network.
VMs continue running. That’s the trap — operators often miss redirected access for hours. On a 10GbE network shared with live migration traffic, storage throughput for affected VMs drops substantially. For I/O-intensive workloads the degradation is noticeable immediately.
Backup jobs are a common trigger — backup agents install filter drivers that interfere with direct CSV I/O. If you’re seeing redirected access appearing consistently after backup windows, see Hyper-V Backup: VSS, Checkpoints, and Restore Failures Explained. If the backup agent left orphaned AVHDX files on the CSV, that’s a separate problem covered in Hyper-V Checkpoint & AVHDX Troubleshooting.
Two distinct causes: an incompatible filter driver (usually AV or backup agent) or an actual storage path failure. They produce different Event IDs and need different fixes.
Event Reference Table
| Event ID | Meaning | Where to look |
|---|---|---|
| 5120 | CSV storage path failure | System log, cluster log |
| 5125 | Redirected access — filter driver | System log |
| 5157 | CSV paused or offline | System log, cluster log |
| 1135 | Node removed from cluster membership | System log |
| 1673 | Node isolation — network not internally connected | System log |
| 1177 | Quorum lost — cluster service shutting down | System log |
Event 5125 — Incompatible Filter Driver
Event ID 5125: the CSV enters redirected access and the message mentions STATUS_CONNECTION_DISCONNECTED. Despite the message, this is usually a filter driver problem, not a network problem.
Antivirus products and backup agents install kernel-level filter drivers that intercept I/O. If the driver isn’t CSV-aware, Windows routes CSV I/O away from the direct path to protect data consistency. In production clusters, Event 5125 appearing shortly after a third-party AV update is a recognized pattern — the update replaces a CSV-compatible driver version with one that isn’t.
fltmc
# Compare against a healthy node to identify outliers
# Look for third-party entries not present on the working node
Filter Name Num Instances Altitude Frame
----------- ------------- -------- -----
WdFilter 13 328010 0
storqosflt 1 244000 0
FileMon 4 259995 0 ← third-party backup agentCross-reference third-party drivers against the vendor’s CSV compatibility documentation. Common culprits: older Veeam transport service versions, Symantec file system filter, Trend Micro VSAPI.
# Detach to confirm (maintenance window only — not zero-risk on live volume)
fltmc detach <filtername> <volume>
# After resolving root cause — resume the CSV
Resume-ClusterResource -Name "Cluster Disk 1"
# Healthy output after resuming
Get-ClusterSharedVolume
Name State FileSystemRedirectedIOReason
---- ----- ----------------------------
Cluster Disk 1 Online NotRedirectedIf the CSV immediately re-enters redirected access after resuming, the underlying cause hasn’t been resolved.
Event 5120 — Storage Path Errors
Event ID 5120 indicates the node failed to communicate with the CSV storage path. The status code identifies the failure type:
| Status code | Meaning | Investigation path |
|---|---|---|
c00000b5 (STATUS_IO_TIMEOUT) | Storage target not responding in time | Check iSCSI/FC target health, network latency, HBA errors |
c00000be (STATUS_BAD_NETWORK_PATH) | Storage network path broken | Check storage network switch logs, NIC teaming health |
c000020c (STATUS_CONNECTION_DISCONNECTED) | Storage connection dropped | Check iSCSI initiator logs, multipath config, HBA firmware |
# Check iSCSI Initiator logs alongside cluster log
Get-WinEvent -LogName "Microsoft-Windows-iSCSI/Operational" -MaxEvents 50 |
Where-Object { $_.LevelDisplayName -eq "Error" -or $_.LevelDisplayName -eq "Warning" }
# Cluster log for the window around Event 5120
Get-ClusterLog -Destination C:\ClusterLogs -TimeSpan 155120 events that correlate with backup job windows usually indicate storage contention, not hardware failure. Contention during backup is a capacity and scheduling problem — not a reason to chase iSCSI configuration.
CSV Offline and Node Isolation
Event 5157 — CSV Paused or Offline
Event 5157 indicates a CSV was paused or taken offline. Different from redirected access — the CSV is not serving I/O at all.
Get-ClusterSharedVolume | Select Name, State, OwnerNode
Get-ClusterLog -Destination C:\ClusterLogs -TimeSpan 30Review cluster log entries immediately before Event 5157. The sequence — which resource failed first, whether it was a disk resource or a network event — determines whether this is a storage failure or a node communication failure.
Node Isolation — Events 1135 and 1673
Event 1135: “Cluster node was removed from the active failover cluster membership.” Event 1673: “The cluster network is not internally connected.”
An isolated node may still be running VMs — the cluster has just stopped trusting it. Node isolation and node failure have different recovery paths, and conflating them is how VHDX corruption happens.
- Determine actual power state of the isolated node via IPMI/iDRAC/iLO — do not rely on ping or WinRM
- If the isolated node is still powered on: do not force quorum — the cluster may try to restart VMs on surviving nodes while the isolated node is still running them
- If reachable via IPMI, attempt graceful shutdown of the isolated node first
- Test cluster heartbeat port:
Test-NetConnection -ComputerName "IsolatedNode" -Port 3343 - If network is the cause, restore connectivity before any quorum operation
- Only after confirming the isolated node is powered off: proceed with quorum recovery if needed
Quorum Lost
Why Quorum Was Lost — Diagnosis
Event 1177: “The Failover Clustering feature will be shut down. This is because a quorum is not currently active in the cluster.”
Common causes, in order of how often they appear:
- Two-node cluster with no witness. One node reboots for patching. Quorum is lost. This is the most preventable cluster failure.
- Witness failure. File share witness went offline, cloud witness lost connectivity, disk witness volume degraded.
- Network partition. Nodes can’t communicate but are all still running. The cluster shuts down the minority partition.
# Collect cluster log — extend TimeSpan to cover the incident window
Get-ClusterLog -Destination C:\ClusterLogs -TimeSpan 60
# Filter for quorum events
Select-String -Path C:\ClusterLogs\*.log -Pattern "quorum" | Select-Object -Last 50
# Check node vote weights
Get-ClusterNode | Select Name, State, NodeWeight, DynamicWeightCollecting Cluster Logs Before Escalation
If this is going to a Microsoft support case, collect these before opening the ticket:
# Full cluster log (last 4 hours)
Get-ClusterLog -Destination C:\ClusterLogs -TimeSpan 240
# Cluster validation report
Test-Cluster -ReportName C:\ClusterLogs\ValidationReport
# System event logs from all nodes (run on each node)
Get-WinEvent -LogName System -MaxEvents 500 |
Export-Csv C:\ClusterLogs\System-Events-HV01.csv -NoTypeInformation
# Cluster resource state snapshot
Get-ClusterResource | Select Name, State, OwnerNode |
Export-Csv C:\ClusterLogs\ClusterState.csv -NoTypeInformationThe cluster log (cluster.log) is the most important artifact for quorum and CSV failures. It records internal cluster events at millisecond granularity — including the exact sequence that led to quorum loss, which the Event Viewer logs don’t preserve. Microsoft support will ask for it immediately.
Witness Type Decision
| Witness type | Best fit | Avoid when |
|---|---|---|
| Cloud witness (Azure Blob) | Geographically dispersed clusters, no shared storage witness | No reliable internet connectivity from cluster nodes |
| File share witness | Two-node clusters at same site, existing file server available | File server is on the same failure domain as cluster nodes |
| Disk witness | Clusters with shared storage, dedicated small LUN available | Cluster has no shared storage |
Two-node clusters need a witness — always. For cluster design rationale and initial witness configuration, see Hyper-V Failover Clustering Explained: Quorum, CSV, and Live Migration.
Emergency Recovery — FixQuorum
Start-ClusterNode -FixQuorum forces the cluster to start with whatever nodes are currently available. It’s the correct tool for a specific scenario. In the wrong scenario, it produces corrupted VHDX files.
FixQuorum with an isolated node still powered on. Running Start-ClusterNode -FixQuorum while the isolated node is still running puts both nodes in a state where each believes it owns shared storage. This is split-brain. At minimum: corrupted VHDX files. In practice: unrecoverable VM state on whichever node’s writes lose the race to the same LUN.
Pre-action checklist — before running FixQuorum
- Confirm failed node is powered off — check IPMI/iDRAC/iLO, not just “no ping”
- Confirm no VMs are running on the failed node
- Confirm shared storage (CSV/SAN) is not mounted on the failed node
- Document which VMs were running on the failed node before failure
- Have a rollback plan before executing
# Run on the surviving node after completing checklist
Start-ClusterNode -Name "HV01" -FixQuorum
# Verify before starting any VMs
Get-ClusterNode
Get-ClusterSharedVolume
Get-ClusterResource | Select Name, State
# Do not start VMs until CSV shows Online / NotRedirectedCluster Database Corruption — 0x80070490
Error 0x80070490 during cluster service startup: “Element not found.” The cluster service can’t read its own configuration store.
# Step 1: Stop Cluster Service on all nodes
Stop-Service ClusSvc -Force
# Step 2: Check for database backup
dir $env:SystemRoot\Cluster\CLUSDB*
# Step 3: Replace corrupted DB with backup
Copy-Item $env:SystemRoot\Cluster\CLUSDB.BAK $env:SystemRoot\Cluster\CLUSDB
# Step 4: Start cluster service on that node first
Start-Service ClusSvc
# Step 5: If successful, start remaining nodes
Start-ClusterNode -Name "HV02"If no valid backup exists, cluster rebuild is the recovery path. This is the scenario where a documented cluster configuration export would have mattered.
Antivirus Exclusions for Clustered Hyper-V
Path-based AV exclusions don’t work reliably for CSV volumes. C:\ClusterStorage\Volume1 is a reparse point — exclusions on the reparse path may not apply when the storage subsystem accesses the volume directly via Volume GUID.
# Get Volume GUID for each CSV
Get-ClusterSharedVolumeState | Select Name, VolumeGuid
# Use this format for AV exclusions:
# \\?\Volume{xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}\| Path / process | Reason |
|---|---|
\\?\Volume{GUID}\ | CSV volumes — use GUID format, not reparse path |
C:\ProgramData\Microsoft\Windows\Hyper-V\ | VM configuration files |
C:\Users\Public\Documents\Hyper-V\Virtual hard disks\ | Default VHDX location |
C:\ClusterStorage\ | Reparse root — supplement with Volume GUID exclusions |
vmms.exe | Hyper-V management service |
vmwp.exe | Per-VM worker processes |
Real-time scanning of VHDX files is the most common cause of both storage performance degradation and CSV redirected access in clustered Hyper-V environments. Microsoft’s antivirus exclusion guidance for Hyper-V covers the full recommended list. If fltmc identifies an AV filter driver as the Event 5125 culprit, the VHDX real-time scan configuration is where to start.
Prevention
Most failures covered in this guide are preventable with cluster hygiene that’s easier to implement during initial setup than after the first incident.
Odd vote count before production. Even in a two-node cluster — add a cloud witness during setup. It costs nothing and removes the most common quorum failure mode.
Patch parity across nodes. Nodes on different Windows Server patch levels have produced delegation failures and config version mismatches. Patch all nodes in a single maintenance window. Staggered patching over weeks creates a window of asymmetric state that’s hard to debug.
Test live migration before you need it. Migrate a non-critical VM across all node pairs during cluster setup. A hyper-v live migration failed error discovered in a test window is a configuration problem with time to fix. The same error discovered during an emergency is an incident.
Centralize vSwitch naming. vSwitch name mismatches cause more hyper-v live migration failed errors than authentication problems do. A naming standard documented somewhere the team can reference eliminates this entirely.
FAQ
Why is Hyper-V live migration failing?
The progress percentage at failure is the fastest diagnostic signal. Under 10% points to a vSwitch name mismatch. Between 10–30% points to Kerberos or CredSSP authentication. Between 30–60% points to CPU compatibility or config version. Over 60% points to CSV or storage state. Start with the pre-migration checklist before digging into specific error codes — most hyper-v live migration failed errors trace back to one of the checklist items.
How do I fix Kerberos authentication errors in Hyper-V live migration?
Check constrained delegation on both node computer accounts in Active Directory. Each node must be allowed to delegate to cifs and Microsoft Virtual System Migration Service on every other node. Also check the Create symbolic links user right — if it’s restricted to Administrators only via GPO, the Hyper-V migration service account won’t have the right even with delegation correctly configured. This is a common miss that causes hyper-v live migration failed with 0x80070569.
Why does live migration fail at less than 10%?
vSwitch name mismatch. The virtual switch name on the destination doesn’t match what the VM is connected to on the source. Names are case-sensitive. Run Get-VMSwitch on both nodes and compare. Rename the outlier to match the cluster standard.
Can I live migrate a VM between different CPU generations?
Yes, with compatibility mode enabled. Set-VMProcessor -VMName "VMName" -CompatibilityForMigrationEnabled $true limits the VM to the common CPU feature set across nodes. The tradeoff: the VM can’t use CPU instructions specific to the newer generation. For most workloads this is acceptable; for compute-heavy workloads that specifically benefit from newer instruction sets, test the performance impact before enabling cluster-wide.
What is CSV redirected access and how do I fix it?
Redirected access means a node is routing CSV I/O through another node over the cluster network instead of accessing storage directly. VMs continue running at degraded performance. Check Event ID 5125 for filter driver issues (run fltmc), and Event ID 5120 for storage path failures. Fix the root cause first, then resume the CSV with Resume-ClusterResource. If CSV re-enters redirected access immediately after resuming, the underlying cause is still present.
Why is my CSV in redirected access after a backup?
Backup agents install kernel filter drivers that intercept storage I/O. If the driver isn’t CSV-aware, Windows routes CSV I/O to redirected mode. Check Event ID 5125 and run fltmc on the affected node to identify the driver. Cross-reference the agent version against the vendor’s CSV compatibility documentation. Updating the backup agent to a CSV-compatible version resolves this in most cases. See also: Hyper-V Backup: VSS, Checkpoints, and Restore Failures Explained.
What causes Event ID 5120 on a cluster shared volume?
The node couldn’t communicate with CSV storage. The status code in the event identifies the failure type: c00000b5 is a storage timeout, c00000be is a bad network path, c000020c is a dropped connection. 5120 events that correlate with backup job windows usually indicate storage contention, not hardware failure.
How do I recover a Hyper-V cluster that lost quorum?
First determine why quorum was lost — which node failed, whether the witness was reachable, whether the cluster network partitioned. If the failed node is confirmed powered off and not running VMs, use Start-ClusterNode -FixQuorum on a surviving node. If the failed node’s power state is unknown, determine it via IPMI before proceeding. FixQuorum while the isolated node is still powered on with shared storage mounted risks split-brain and VHDX corruption.
Is it safe to use Start-ClusterNode -FixQuorum?
Only when the failed node is confirmed powered off — not just unreachable, confirmed off via IPMI/iDRAC/iLO. If the node might still be running VMs with shared CSV mounted, resolve that first. The two minutes spent confirming power state are not optional.
What antivirus exclusions are needed for clustered Hyper-V?
Use Volume GUID exclusions for CSV volumes (\\?\Volume{GUID}\), not path-based exclusions on C:\ClusterStorage. Path-based exclusions on reparse points are unreliable at the storage subsystem level. Exclude VMMS (vmms.exe) and per-VM worker processes (vmwp.exe). Real-time VHDX scanning is the most common cause of CSV entering redirected access — if Event 5125 appears after an AV update, that’s where to start.
Hyper-V Series
12 articles — Windows Server 2025 · Networking · Storage · Backup · Clustering