
Adding proxmox shared storage to a cluster is one of those decisions that looks straightforward until a VM needs to move between nodes and nothing works. The backend you pick determines what live migration looks like, what HA can do, and how many failure domains you’re managing at once.
This article covers how NFS, iSCSI, and Ceph integrate with Proxmox VE — where each option fits, what breaks when something goes wrong, and which one belongs in your environment.
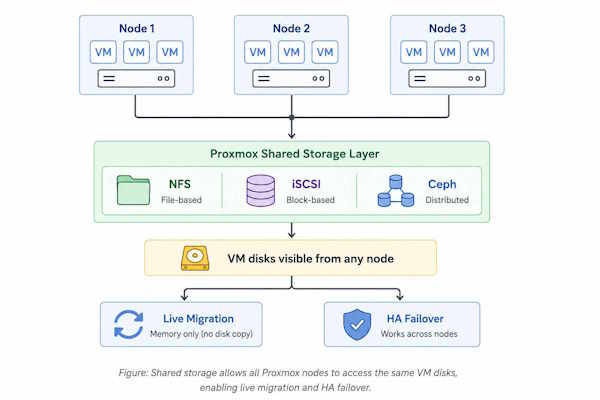
- Proxmox shared storage is required for live migration without disk copy and for Proxmox HA
- NFS is the simplest path — right for homelab, ISO/template libraries, and backup targets; the NFS server is a single point of failure
- iSCSI delivers block access with lower latency — requires LVM on top of the LUN and multipath to avoid single-path risk
- Ceph eliminates the external storage dependency and handles its own HA — minimum three nodes, 10GbE, and real operational investment
- For most small clusters: NFS for backups and ISOs, local ZFS for VM disks
Why Live Migration and HA Depend on Shared Storage
Proxmox live migration has two modes. If a VM’s disk lives on local storage, the entire disk image copies across the network before the VM starts on the target node — slow, disruptive, and often impractical for large disks. If the disk lives on proxmox shared storage, both nodes already see it. Only the memory state moves. Migration completes in seconds rather than minutes.
Proxmox HA uses the same logic. When a node fails, the HA manager restarts its VMs on a surviving node. That only works if the surviving node can access the VM’s storage. Local storage on the failed node is inaccessible. Proxmox shared storage is not.
The decision isn’t “do I want shared storage?” — it’s “which VMs need it and why?”
What “Shared” Means in the Proxmox Cluster Model
Proxmox storage configuration lives in /etc/pve/storage.cfg, replicated automatically to all cluster nodes via pmxcfs. Every node sees the same storage definitions. Whether a node can actually mount and use a backend is a separate question — one that depends on network access and backend type.
A backend marked shared in Proxmox means all cluster nodes access the same data directly. This is the technical requirement for live migration without disk copy and for HA. Backends not marked shared are node-local; VM migration requires a full disk transfer first.
When local storage is enough:
- Single-node setup — no migration needed
- VMs that can tolerate offline migration (full disk copy)
- Development environments where downtime is acceptable
When proxmox shared storage becomes necessary:
- Live migration without noticeable disruption
- Proxmox HA — VMs must restart on another node after failure
- ISO libraries and VM templates that all nodes need to access
Failure Domains: Where Each Option Moves the Risk
Every proxmox shared storage solution moves the failure domain somewhere. It doesn’t eliminate it — it relocates it. Understanding where your failure domain lands is the real architectural decision here.
| Storage | Failure Domain | What fails when it goes down |
|---|---|---|
| NFS | NFS server | All VMs on that share freeze; HA cannot restart them elsewhere |
| iSCSI | SAN + each network path | Single-path loss hangs I/O; SAN failure drops all connected VMs |
| Ceph | Distributed across the cluster | Individual node or disk failure is tolerated; cluster-wide network failure is not |
NFS moves the failure domain to the NAS. iSCSI moves it to the SAN and the network path between host and target. Ceph distributes it across the cluster — the failure domain grows along with the hardware investment required to manage it.
NFS: The Simple Path
NFS is a file-based network protocol. The NFS server exports a directory; Proxmox mounts it as a filesystem path on each node. Every cluster node mounts the same share simultaneously, which satisfies the proxmox shared storage requirement without any additional layer on top.
How NFS Integrates with Proxmox
Add NFS through Datacenter → Storage → Add → NFS. Specify the server IP, export path, and a storage ID. Proxmox handles mounting at /mnt/pve/<ID> and replicates the configuration to all nodes automatically via storage.cfg. No /etc/fstab entries needed — Proxmox manages mounts directly. The full list of supported content types and NFS options is documented in the Proxmox NFS storage reference.
nfs: nfs-store
server 192.168.1.100
export /export/pve
path /mnt/pve/nfs-store
content images,iso,backupUse the server’s IP address, not its hostname. DNS resolution adds a failure dependency that serves no purpose here — if DNS is slow at boot, Proxmox can’t mount the share, and the cluster node starts in a degraded state.
What NFS Handles Well — and Where It Breaks
NFS proxmox shared storage is well-suited for ISO and template libraries (read-heavy, low latency sensitivity), backup targets for Proxmox Backup Server, and small clusters where all VMs fit on one reliable NAS. It’s the simplest path to a working multi-node shared storage setup. For more on how NFS fits into a broader backup architecture, see Proxmox Backup Strategy.
NFS degrades under high-IOPS workloads — databases, write-intensive VMs — where file-layer overhead adds latency compared to block access. Under concurrent parallel I/O from many VMs, the NFS server becomes the bottleneck. Forum threads from operators who’ve run production databases on NFS share a consistent pattern: performance is acceptable until it suddenly isn’t, and diagnosing the ceiling takes longer than the initial setup did.
NFS Failure Modes
- NAS reboot or NFS service crash — all VMs with disks on the share freeze immediately; I/O blocks at the guest OS level; Proxmox cannot compensate
- DNS resolution failure — if hostname was used instead of IP, Proxmox cannot remount after restart; always use IP addresses in
storage.cfg - Network interruption between node and NFS server — same effect as a NAS crash from the VM’s perspective
- NFS export permission change on server side — mount appears active but writes fail silently or return permission errors inside the guest
- Stale NFS handle after server restart — existing mounts return
ESTALEerrors; remount withpvesm unmount <ID>thenpvesm mount <ID>
Making NFS highly available as a proxmox shared storage backend requires HA on the NFS server side — clustered NAS, ZFS replication with automatic failover via CARP/virtual IP, or equivalent. Proxmox detects an unavailable share and alerts, but it cannot restart VMs elsewhere if the shared storage itself is the failure.
NFS Verification
# Storage active on all nodes
pvesm status
# Mount is live
df -h | grep /mnt/pve/nfs-store
# Verify export is visible from this node
showmount -e 192.168.1.100
# Check latency — nfs-utils package required
nfsiostat 1 5Sustained latency above 10–20ms on nfsiostat indicates a network or server problem worth investigating before placing production VMs on the share.
iSCSI: Block Storage Over the Network
iSCSI presents a block device (a LUN) over IP. Proxmox connects as an iSCSI initiator using open-iscsi, discovers the target, and maps the LUN as a raw block device. Unlike NFS-based proxmox shared storage, iSCSI delivers at the block level — lower latency, higher throughput, no file-layer overhead. The tradeoff: raw block access alone isn’t usable. You need a volume manager on top of the LUN.
How iSCSI Works as Proxmox Shared Storage
All cluster nodes connect to the same iSCSI target and see the same LUN. When LVM is configured on top of that LUN, all nodes see the same volume group. VM disks created as logical volumes are accessible from any node — satisfying the proxmox shared storage requirement at the block layer.
# storage.cfg — required two-layer approach
iscsi: my-iscsi
portal 192.168.1.200
target iqn.2006-01.org.freenas.ctl:mytarget
content none
lvm: iscsi-vms
vgname vg-iscsi
base my-iscsi:0.0.0.0.0.0.0.0.1
content images
shared 1The content none on the iSCSI entry tells Proxmox not to store anything on the raw LUN directly. The LVM layer on top is where VM disks live. This two-layer approach is not optional — raw iSCSI LUNs without LVM are not usable for VM disk images in Proxmox.
Multipath: Why Single-Path iSCSI Is a Risk
A single iSCSI connection means a single network path. One failed NIC, one failed switch port, one misconfigured VLAN — the session drops and every VM with disks on that target loses storage access immediately. For any proxmox shared storage setup running production VMs, multipath is the difference between a failover and an outage.
Multipath I/O (multipath-tools) maintains multiple independent network paths to the same LUN. If one path fails, I/O continues over the remaining path without VM interruption.
# Verify multipath paths
multipath -ll
# Expected: multiple paths, both active ready
# 360014050a35f9e6b1234abcd
# └─┬─ 8:0:0:1 sdb 8:16 active ready running
# └─ 9:0:0:1 sdc 8:32 active ready runningIf multipath -ll shows a single path, you have a single point of failure regardless of what the SAN documentation says about redundancy.
iSCSI Failure Modes
- Single path loss (no multipath configured) — iSCSI session disconnects; VMs freeze waiting for I/O; requires session reconnect or node reboot to recover
- CHAP misconfiguration — authentication failure on reconnect; session doesn’t re-establish after SAN restart; check
/var/log/syslogfor CHAP errors - LUN ID shift after SAN reconfiguration — LUN numbering changes after firmware update or pool resize; LVM fails to find its physical volume; verify with
pvs - Target unreachable —
iscsiadm -m sessionshows disconnected state; VMs freeze; check network and portal address instorage.cfg - Multipath duplicate WWID conflict — after SAN migration or LUN clone, multipath sees conflicting device IDs; update
/etc/multipath.conf
iSCSI Verification
# iSCSI target discovery
iscsiadm -m discovery -t st -p 192.168.1.200
# Active sessions
iscsiadm -m session
# LVM physical volumes visible
pvs
# Volume group status
vgs
# Proxmox storage status
pvesm statusCeph: Distributed Storage Built Into Proxmox
Ceph is architecturally different from NFS and iSCSI proxmox shared storage options. Rather than presenting a share or a LUN from an external server, Ceph distributes data across the disks of multiple nodes simultaneously. There is no single storage server — the cluster itself is the storage. Proxmox includes Ceph installation and management tools natively; a hyper-converged deployment runs compute and storage on the same physical nodes.
What Ceph Provides That NFS and iSCSI Don’t
- No external storage dependency — the Proxmox nodes are the storage
- Built-in replication — data is written to N nodes simultaneously (default: 3 replicas); losing a node doesn’t lose data
- Native snapshots and clones — RBD supports snapshots and cloning at the storage layer without a SAN
- Self-healing — when an OSD fails, Ceph automatically rebalances data across remaining OSDs
- Horizontal scale — add nodes and disks; Ceph absorbs them
For detailed Ceph internal architecture — CRUSH maps, placement groups, pool configuration — see Proxmox Storage: ZFS vs LVM-thin vs Ceph. This section focuses on Ceph as a proxmox shared storage backend in a cluster context.
The Complexity Cost — What Ceph Actually Requires
Minimum viable Ceph for production proxmox shared storage:
- 3 physical nodes — quorum requirement for monitors; 2 nodes is not viable
- 10GbE networking — 1GbE makes Ceph painful under any real workload
- Dedicated disks per OSD — mixing OSD and OS on the same disk is technically possible but degrades performance significantly
- ~8GB RAM per OSD daemon, plus node workload overhead
- 2–4 CPU cores per OSD under sustained I/O
Operators who deploy Ceph on 1GbE or with 2 nodes document a consistent experience: degraded performance, slow rebalancing after any disk change, frequent HEALTH_WARN states. These aren’t conservative suggestions — they’re operational thresholds below which Ceph becomes harder to operate than the problem it solves.
Ongoing operation requires understanding Ceph health states, OSD management, PG distribution, and recovery procedures. As the Proxmox documentation on hyper-converged Ceph notes, this deployment model is recommended for experienced operators. The Ceph storage devices documentation covers OSD hardware recommendations in detail.
Ceph Failure Modes
- OSD failure — single disk loss; Ceph enters
HEALTH_WARN, begins automatic rebalancing; cluster continues serving I/O with remaining replicas; checkceph osd tree - Network saturation during rebalancing — after OSD loss, Ceph rebalances data across remaining OSDs; on 1GbE this saturates the network and degrades all VM I/O simultaneously
- PG recovery backlog — large number of degraded placement groups after multiple failures; cluster may enter read-only mode if too many PGs are inactive; check
ceph pg dump | grep -v active+clean - Monitor quorum loss — if majority of MON daemons are unreachable, the cluster stops accepting writes; minimum 3 monitors prevents single-MON loss from causing quorum failure
- Pool full (nearfull / full threshold) — Ceph stops writes when pool hits capacity;
ceph dfshows usage; requires adding OSD capacity or temporarily lowering replica count
When Ceph Is the Right Call (and When It Isn’t)
Ceph proxmox shared storage is right for clusters of 3+ nodes where storage HA without an external SAN is a hard requirement, for environments with 10GbE and teams with operational bandwidth to manage a distributed system, and for workloads where native snapshots and cloning at the storage layer justify the infrastructure investment.
It’s wrong for 2-node homelab clusters (3 nodes minimum, no exceptions), environments with 1GbE and no upgrade path, and setups where operational simplicity matters more than features. A homelab running Ceph on 3 mini PCs with 10GbE SFP+ and NVMe OSDs is functional and well-understood. A homelab running Ceph over 1GbE consumer switches is a performance problem waiting to surface at the worst time.
Ceph Verification
# Cluster health — must be HEALTH_OK before placing VMs
ceph -s
# OSD status
ceph osd tree
# Capacity distribution
ceph df
# Per-OSD performance
ceph osd perfHEALTH_OK is the only acceptable Ceph cluster status before placing workloads on the storage. Placing additional VMs on a HEALTH_WARN cluster accelerates the underlying problem.
Comparison: NFS vs iSCSI vs Ceph as Proxmox Shared Storage
| Feature | NFS | iSCSI | Ceph |
|---|---|---|---|
| Storage type | File (NFSv3/4) | Block (SCSI LUN) | Distributed object/block/file |
| Shared storage for cluster | Yes | Yes (with LVM) | Yes |
| Live migration support | Yes | Yes | Yes |
| External dependency | NFS server | SAN / iSCSI target | None (built-in) |
| Native snapshots | NAS-side only | SAN-side only | Yes (RBD) |
| Single point of failure | NFS server | SAN or single path | No (3+ nodes) |
| Minimum viable setup | 1GbE, NAS | 1GbE, SAN/NAS | 3 nodes, 10GbE |
| Setup complexity | Low | Medium | High |
| Operational overhead | Low | Medium | High |
Proxmox Shared Storage by Environment Type
| Scenario | Recommendation | Why |
|---|---|---|
| Single node | Local ZFS | No migration needed; shared storage adds complexity without benefit |
| 2 nodes, existing NAS | NFS | Simplest shared access; NFS server is SPOF — acceptable tradeoff at this scale |
| 3 nodes, existing NAS | NFS for ISO/backup, local ZFS for VM disks | Most homelab VMs don’t need live migration; NFS handles shared libraries well |
| 3+ nodes, existing SAN | iSCSI with LVM + multipath | Leverages existing infrastructure; better block performance than NFS |
| 3+ nodes, 10GbE, want full HA | Ceph | Eliminates external storage dependency; built-in HA for compute and storage together |
Shared Storage Validation Checklist
- ☐ Storage shows
activeon every cluster node —pvesm status - ☐ Storage visible and mounted —
df -h | grep /mnt/pve/ - ☐ Test VM migration succeeds between nodes (memory only, no disk copy)
- ☐ Storage remounts correctly after node reboot
- ☐ HA test completed — simulate node failure, confirm VM restarts on surviving node
- ☐ Monitoring configured — latency and availability alerts active
- ☐ iSCSI only: multipath active, both paths show
active ready - ☐ Ceph only:
ceph -sreturnsHEALTH_OK
FAQ
Does Proxmox require shared storage for live migration?
For live migration without disk copy, yes. With proxmox shared storage, only the memory state transfers and migration completes in seconds. With local disk, Proxmox copies the entire disk image first — possible, but slow and disruptive for large VMs. The Proxmox HA Cluster guide covers how shared storage integrates with HA configuration.
Can I use NFS for VM disks in a Proxmox cluster?
Yes. NFS is fully supported for VM disk images. The practical constraint is that the NFS server becomes a single point of failure for all VMs stored there. Acceptable for homelab use; in production, requires HA on the NFS server side — clustered NAS, ZFS replication with automatic failover, or equivalent.
What is the minimum setup for iSCSI in Proxmox?
The open-iscsi package on each Proxmox node, a target server presenting a LUN, network connectivity, and LVM configured on top of the LUN. For production: add multipath-tools and configure at least two independent network paths to the target. Single-path iSCSI is a risk, not a starting point.
When does Ceph make sense for a Proxmox cluster?
Three or more physical nodes, 10GbE networking, dedicated disks for OSD, and the operational bandwidth to manage a distributed storage system. If any of those conditions aren’t met, NFS or iSCSI proxmox shared storage will be more reliable in practice.
What happens to VMs if the NFS share becomes unavailable?
I/O from affected VMs blocks immediately. Guest OSes see storage errors or freeze depending on workload. Proxmox cannot automatically migrate VMs off an unavailable storage backend. Recovery requires restoring NFS server availability or force-stopping VMs manually.
Can I use Proxmox HA without shared storage?
No. Proxmox HA requires the surviving node to access the failed node’s VM disks. That’s only possible with proxmox shared storage. VMs on local-only storage cannot be protected by HA, regardless of how the cluster is configured.
Is iSCSI faster than NFS for Proxmox VM storage?
Generally yes, for random I/O and write-intensive workloads. iSCSI operates at the block level; NFS adds a file-layer translation stack. The difference is most visible under database workloads or high-concurrency I/O. For sequential reads — ISO storage, template access — the gap is much smaller.
Final Thoughts
For most small Proxmox clusters, the practical answer is simpler than the options list suggests. Local ZFS on each node handles VM disks well. A reliable NAS with NFS covers ISO libraries, templates, and backup targets. That combination serves a 2–3 node homelab as proxmox shared storage without requiring a SAN or a Ceph cluster.
iSCSI makes sense when existing SAN infrastructure is already in place and block-level performance matters. The complexity is manageable when multipath is configured correctly from the start — retrofitting it into a running iSCSI deployment is messier than doing it right initially.
Ceph is the right choice when storage HA without external dependencies is a hard requirement and the hardware supports it. The capabilities are genuinely better than NFS and iSCSI for production workloads at scale. The operational cost is also genuinely higher. Treat it as a platform decision, not a storage configuration task.
Related reading: Proxmox Storage: ZFS vs LVM-thin vs Ceph covers local and distributed storage backends in depth. Proxmox HA Cluster covers how proxmox shared storage integrates with HA configuration and quorum requirements. Proxmox Backup Strategy covers NFS and PBS as backup targets in practice.
Proxmox VE Series
22 articles — Installation · Storage · Networking · HA · Recovery