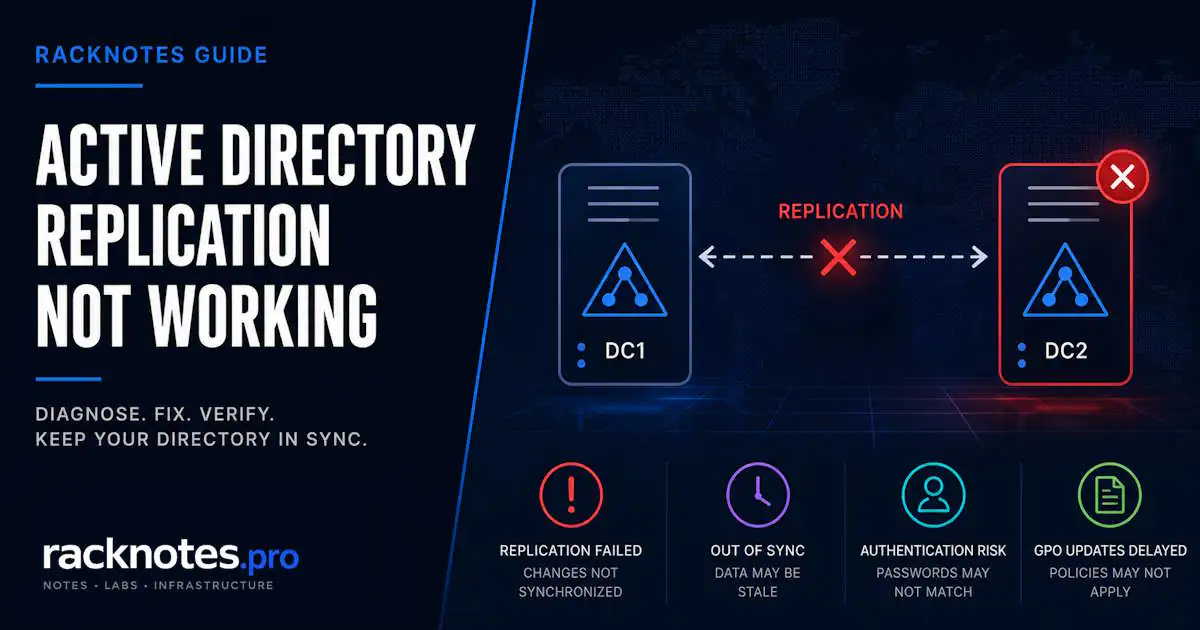
When active directory replication is not working, the problem in a single-DC environment is obvious immediately. In a multi-DC environment, broken replication can run silently for hours — or days — before something visible fails. A user authenticates against DC2, which hasn’t replicated a password change from DC1 in six hours. A GPO update applied Monday morning hasn’t reached half the site by Tuesday. A new account created on DC1 doesn’t exist on DC2. The replication engine stopped, and nothing alerted you.
Active directory replication not working is one of those failures where the blast radius is much wider than the symptom that surfaced it.
- When active directory replication is not working, start with
repadmin /replsummary— any non-zero value in the Fails column means replication is broken to that DC pair - DNS misconfiguration and time skew account for the majority of active directory replication not working cases — check these before touching topology
- Error 1722 (RPC Unavailable) = network or DNS; Error 8453 (Access Denied) = time skew or trust failure
- Lingering objects occur when a DC is offline longer than the tombstone lifetime (default 180 days)
- USN rollback from a VM snapshot restore requires DC demotion — it cannot be repaired in place
- Force replication with
repadmin /syncall /AdePonly after the root cause is resolved, not before
repadmin /replsummaryshows 0 failures across all DC pairsdcdiag /test:replicationspasses on every DCdcdiag /test:DNS /vpasses — no SRV record failures- No Event ID 1865 or 1925 in the Directory Service log
- All DCs synchronized to domain time — w32tm /query /status shows no skew
- Test user created on DC1 replicates to DC2 within 30 seconds
What Breaks When Active Directory Replication Is Not Working
Replication carries more than user accounts. When it stops, the following stop synchronizing across DCs:
- Password changes — a user changes their password on DC1; DC2 still has the old hash. Authentication against DC2 fails or succeeds with the wrong credentials depending on timing and Kerberos ticket state.
- Group Policy — GPO updates require both AD replication (for the GPO object) and DFSR replication (for the SYSVOL share). Broken AD replication stops the object half of this pair.
- New accounts and group memberships — accounts created or modified on DC1 don’t exist or don’t update on DC2 until replication runs.
- Kerberos service tickets — changes to service accounts and SPNs don’t propagate, which can break application authentication silently.
The earlier you catch replication failures, the smaller the cleanup. A DC that’s been out of sync for a week requires careful remediation before you force-sync — you may be pushing stale data in the wrong direction.
AD Replication vs. SYSVOL Replication — Active Directory Replication Not Working Doesn’t Always Mean DFSR Is Broken
This distinction causes operators to declare victory too early. Active directory replication not working (handled by the AD DS replication engine, monitored with repadmin) refers to the pipeline carrying AD objects: users, groups, GPO metadata, computer accounts. SYSVOL replication (handled by DFSR on Windows Server 2008+) carries the actual GPO files and logon scripts stored in the SYSVOL share.
A healthy repadmin /replsummary does not confirm SYSVOL is healthy. Both pipelines can fail independently. If users are getting authentication correct but Group Policy isn’t applying, DFSR is the more likely culprit even when AD replication looks clean.
Check DFSR status separately:
dfsrdiag ReplicationState
dfsrdiag backlog /RGName:"Domain System Volume" /RFName:SYSVOL /SendingMember:DC1 /ReceivingMember:DC2If ReplicationState shows a backlog or errors, SYSVOL replication has its own failure path. The SYSVOL replication troubleshooting guide covers DFSR diagnostic workflows in detail.
Step 1 — Get the Overview (Active Directory Replication Not Working Triage)
repadmin /replsummaryThis is the fastest triage command. It shows replication status across all DC pairs: success count, failure count, and time since last successful replication. The “Fails” column is the key — any non-zero value means replication is broken to that DC pair.
The output shows both source and destination perspective. A DC showing failures only as a destination means the source can’t reach it. A DC showing failures as both source and destination usually points to network or DNS rather than a unidirectional problem.
Step 2 — Get Detailed Error Codes
repadmin /showrepl * /csv > repl.csvThe CSV output captures every replication link across every naming context: Domain, Schema, Configuration, ForestDNSZones, DomainDNSZones. Sort by “Last Failure Status” — non-zero values give the exact error code for each failing link.
More useful than /replsummary for environments with more than two DCs, because it isolates which specific DC-to-DC links are failing and what error each is returning.
To check the current replication queue — objects waiting to replicate — run:
repadmin /queueA large queue that isn’t draining indicates replication is attempted but stalled. An empty queue with failures in /replsummary means the connection itself isn’t being established.
Step 3 — Run DCDiag
dcdiag /test:replications /vVerbose output identifies failures in the Directory Service log and correlates them with the replication topology. The lines to look for:
.....[DC name] passed test Replications— clean.....[DC name] failed test Replications— broken; the lines below include the error code
DCDiag also surfaces issues repadmin won’t catch directly — naming contexts that are failing independently of others, and objects in the replication queue that have stalled without generating a visible summary error. If replication was healthy at deployment, comparing current DCDiag output against the active directory post-install checklist baseline narrows the scope of what changed.
Error Code Reference
These codes appear in the CSV from Step 2 and in DCDiag output. When active directory replication is not working, the error code is the fastest way to narrow the diagnostic path.
| Error | Meaning | Most Likely Cause | First Command |
|---|---|---|---|
| 1722 | RPC Server Unavailable | Network blocking RPC, or DNS not resolving DC name | Test-NetConnection -ComputerName DC2 -Port 135 |
| 1256 | Remote Machine Not Available | DC offline or network unreachable | Ping + Test-NetConnection |
| 8453 | Replication Access Denied | Time skew > 5 min, or LDAP bind failure | w32tm /query /status |
| 8461 | Replication Suspended | Replication intentionally disabled | repadmin /options DC1 |
| 8606 | Insufficient Attributes | Lingering objects present | repadmin /showlingeringobjects |
| 8589 | Cannot derive SPN | DNS or SPN misconfiguration | dcdiag /test:DNS /v |
Event ID Quick Reference
| Event ID | Log | Meaning | Action |
|---|---|---|---|
| 1311 | Directory Service | No replication path found — site topology problem | Check site link config in Active Directory Sites and Services |
| 1865 | Directory Service | DC cannot contact replication partner | Check network + DNS |
| 1925 | Directory Service | Attempt to contact DC failed | DNS resolution check |
| 1988 | Directory Service | Lingering object detected — replication blocked | repadmin /showlingeringobjects |
| 2042 | Directory Service | Tombstone lifetime exceeded — DC too far out of sync | Evaluate demote vs. force-rejoin |
| 2087 | Directory Service | DNS lookup failure — DC cannot resolve partner | dcdiag /test:DNS /v |
| 2088 | Directory Service | DNS fallback used — replication degraded | Fix DNS, don’t rely on fallback |
| 2095 | Directory Service | USN rollback detected | Demote and repromote the affected DC |
Events 1865 and 1925 almost always appear together. Events 2087 and 2088 indicate DNS problems that may not surface in basic connectivity tests — replication is succeeding via fallback, but the root DNS issue will cause harder failures later. Event 2095 is the critical one; other DCs are already refusing the affected DC’s updates.
Diagnosing Network Issues — Active Directory Replication Not Working with Error 1722
Error 1722 is the most common active directory replication not working error code. It means the RPC server on the destination DC is unreachable. Before touching anything in AD, verify the network path:
# From DC1, testing connectivity to DC2:
Test-NetConnection -ComputerName DC2 -Port 135 # RPC Endpoint Mapper
Test-NetConnection -ComputerName DC2 -Port 445 # SMB
Test-NetConnection -ComputerName DC2 -Port 389 # LDAP
Test-NetConnection -ComputerName DC2 -Port 88 # KerberosIf port 135 is open but replication still fails, the issue is usually in the RPC dynamic port range (49152–65535 on Server 2008+). Firewalls that pass 135 but block the dynamic range are a common misconfiguration in environments where someone tightened rules without accounting for AD traffic.
For reference, here are all ports required for AD replication:
| Service | Port | Protocol |
|---|---|---|
| RPC Endpoint Mapper | 135 | TCP |
| RPC Dynamic Range | 49152–65535 | TCP |
| LDAP | 389 | TCP/UDP |
| LDAPS | 636 | TCP |
| SMB | 445 | TCP |
| Kerberos | 88 | TCP/UDP |
| DNS | 53 | TCP/UDP |
| Global Catalog | 3268 | TCP |
| Global Catalog SSL | 3269 | TCP |
Error 1722 that appears only by DNS name (not IP) points directly to DNS. Test name resolution before concluding it’s a firewall issue:
Resolve-DnsName DC2.ad.contoso.com
nslookup DC2.ad.contoso.comIf the name doesn’t resolve, or resolves to the wrong IP, the replication failure is a DNS failure presenting as Error 1722.
- Run
Test-NetConnectionto DC2 on ports 135, 445, 389, 88 — if any fail, the network path is the problem - If all ports pass, test name resolution:
Resolve-DnsName DC2.ad.contoso.com - If DNS fails, run
dcdiag /test:DNS /v— look for SRV record failures and Event 2087 - If DNS resolves but replication still fails, check whether firewall rules allow the RPC dynamic port range (49152–65535)
- Verify the DC is not pointing to itself as its only DNS server — causes silent SRV registration failures after reboots
- Run
repadmin /kccto trigger the Knowledge Consistency Checker and rebuild replication topology — use if topology looks misconfigured after a recent DC add or remove
Diagnosing Time Skew — Active Directory Replication Not Working with Error 8453
Kerberos authentication — which AD replication depends on — rejects tickets if the time difference between DCs exceeds five minutes. When active directory replication is not working with Error 8453 (Replication Access Denied), time skew is the cause more often than actual access control failures.
Check time on each DC:
# Run on each DC:
w32tm /query /status
# Compare across all DCs:
w32tm /monitor /computers:DC1,DC2,DC3The PDC Emulator FSMO role holder is the authoritative time source for the domain. All other DCs sync from it. If the PDC Emulator has drifted from its external reference, the entire domain follows. Force a resync on a non-PDC DC:
w32tm /resync /forceAfter correcting time skew, wait 5–10 minutes and re-run repadmin /replsummary. Kerberos tickets have a short lifetime — most environments recover replication automatically once time is synchronized.
In virtual environments: if DC VMs are running on a hypervisor with incorrect host time, w32tm will fight a losing battle against the VM time sync service. On Hyper-V, verify that VM Integration Services time sync is either properly configured to defer to the PDC Emulator, or disabled so w32tm manages time independently.
Diagnosing DNS Failures That Cause Active Directory Replication Not Working
DNS misconfiguration is the single most common root cause of active directory replication not working — including failures that present as Error 1722 or Event IDs 2087 and 2088 rather than explicit DNS errors.
# Full DNS diagnostic:
dcdiag /test:DNS /v
# Check SRV records manually:
nslookup -type=SRV _msdcs.ad.contoso.com
nslookup -type=SRV _ldap._tcp.ad.contoso.comdcdiag /test:DNS flags missing SRV records, incorrect delegations, incorrect forwarder configuration, and DCs not registering their records. Event IDs 2087 and 2088 in the Directory Service log indicate DNS lookup failures that may not be visible in basic connectivity tests.
The most common misconfiguration: a DC configured with itself as its only DNS server, or with an external DNS server (8.8.8.8) as primary. When the DC restarts, it either fails to register its SRV records or registers them against the wrong DNS zone. Other DCs can’t find it, and active directory replication not working appears as what looks like a network error. Each DC should point to another DC running DNS as primary, with itself as secondary.
For deeper DNS failure investigation — zone delegation, conditional forwarders, and SRV record repair — the active directory dns problems guide covers those workflows.
Lingering Objects — Active Directory Replication Not Working with Error 8606
A lingering object is an AD object that exists on one DC but has been deleted on others — deleted while that DC was offline, with the deletion passing the tombstone lifetime (default 180 days). Active directory replication not working with Error 8606 or Event ID 1988 is the typical presentation. When the DC comes back online, it holds the old object and tries to replicate it.
Detection:
repadmin /showlingeringobjects DC1 DC2 DC=ad,DC=contoso,DC=comThis compares DC1’s view against DC2’s authoritative copy and reports objects that shouldn’t exist. Run this for each naming context: Domain NC, Configuration NC, Schema NC.
Removal:
# Advisory mode first — reports what would be removed, doesn't remove:
repadmin /removelingeringobjects DC1 DC2 DC=ad,DC=contoso,DC=com /advisory_mode
# Execute after reviewing advisory output:
repadmin /removelingeringobjects DC1 DC2 DC=ad,DC=contoso,DC=comAlways run advisory mode first. Review the output before executing. Lingering objects are safe to remove — they’re already deleted from the authoritative DCs — but confirming the scope before removal is good practice.
Prevention: If a DC is going to be offline for more than 60 days, decommission it rather than leaving it idle. Sixty days is a safe buffer below the 180-day tombstone lifetime. Event ID 2042 (tombstone lifetime exceeded) is the signal that a DC has been offline too long to cleanly rejoin — evaluate demote vs. force-rejoin at that point.
USN Rollback — The VM Snapshot Problem
This is the failure scenario that cannot be repaired in place.
A DC VM is rolled back to a snapshot taken weeks earlier — either intentionally or as part of a storage recovery. The DC restarts with an older Update Sequence Number (USN). Other DCs have already processed updates beyond that USN. When the rolled-back DC tries to replicate, partner DCs compare USN vectors, detect the inconsistency, and quarantine the rolled-back DC to prevent data corruption. Event ID 2095 appears in the Directory Service log. Replication to and from that DC stops.
Detection:
# Check Directory Service log for Event 2095:
Get-EventLog -LogName "Directory Service" -EntryType Error | Where-Object {$_.EventID -eq 2095}Event 2095 is definitive. If you see it, the DC has been identified as a USN rollback victim.
Recovery path — demote and repromote:
# Step 1: Confirm other DCs are healthy before proceeding
repadmin /showrepl
# Step 2: Demote the affected DC
Uninstall-ADDSDomainController -DemoteOperationMasterRole:$false
# Step 3: Clean up metadata from AD (run on a healthy DC)
# ntdsutil -> "metadata cleanup" -> "remove selected server"
# Step 4: Repromote
Install-ADDSDomainController -DomainName "ad.contoso.com" -Credential (Get-Credential)Do not attempt to repair a USN rollback by forcing replication or using ntdsutil to reset USN values. This approach circulates in forum threads and causes data corruption. The only supported recovery is demotion and repromote.
Prevention: Never restore a DC VM from a hypervisor snapshot. Use Windows Server Backup with VSS-aware AD backup, or Azure Backup for cloud-connected environments. A Hyper-V checkpoint on a DC VM is an operational risk — not a backup strategy.
Force Replication After Fixing Active Directory Replication Not Working
After resolving the root cause — and only after — force replication to accelerate convergence rather than waiting for the replication schedule:
repadmin /syncall /AdePFlags: /A = all naming contexts, /d = identify servers by distinguished name, /e = enterprise (cross-site), /P = push outbound changes.
This forces synchronization across all DC pairs and all naming contexts in one pass. It can take several minutes in larger environments. Do not run it before fixing the root cause — if DNS is still broken, /syncall propagates the broken state faster and makes recovery more complex.
Verifying Active Directory Replication Is Healthy After a Fix
After resolving active directory replication not working and running /syncall, confirm replication is clean before closing the incident. Most articles stop at “run repadmin /replsummary again.” That’s not sufficient.
- Run
repadmin /replsummary— verify zero failures in the Fails column for all DC pairs - Run
repadmin /showrepl— confirm “Last attempt was successful” for each naming context on each DC pair - Run
dcdiag /test:replications /v— confirm all DCs show “passed test Replications” - Run
dcdiag /test:DNS /v— DNS health and replication health are linked; confirm both are clean - Create a test user on DC1 and verify it appears on DC2 within 30 seconds — confirms the full pipeline, not just the reporting layer
- Run
dfsrdiag ReplicationState— confirm SYSVOL replication is also healthy; AD and DFSR are separate pipelines
Step 5 — creating a test user — is the only check that confirms the full replication pipeline end-to-end. In environments where repadmin shows green but something is still wrong, a live object create-and-verify catches the residual problem.
Step 6 is frequently skipped. AD replication and SYSVOL replication can fail independently. If the AD side is healthy but DFSR is still lagging, Group Policy won’t apply correctly and the incident isn’t closed.
Frequently Asked Questions
What is the first command to run when active directory replication is not working?
repadmin /replsummary. It gives a fast read on which DC pairs are failing and how many failures have accumulated. Takes seconds to run and tells you where to focus before running deeper diagnostics.
What causes Error 1722 in Active Directory replication?
Error 1722 (RPC Server Unavailable) is almost always a network or DNS problem. The destination DC is unreachable, or its DNS name doesn’t resolve to the correct IP. Start with Test-NetConnection on ports 135, 445, and 389 before investigating anything else. Firewalls that block the RPC dynamic port range (49152–65535) cause Error 1722 even when basic connectivity looks fine.
How do I diagnose active directory replication not working across multiple DCs?
repadmin /replsummary for a quick overview. repadmin /showrepl * /csv > repl.csv for a full export of every replication link and its last failure status. dcdiag /test:replications /v for verbose diagnostic output correlated with the Directory Service event log.
Can I force active directory replication manually?
Yes: repadmin /syncall /AdeP. Run this only after fixing the root cause. Running it before the fix propagates the broken state to more DCs faster and makes recovery more complex.
What are lingering objects in Active Directory?
Objects that exist on a DC but have been deleted on others — where the deletion happened while the DC was offline and the tombstone lifetime has since expired. Event ID 1988 flags them. Detected with repadmin /showlingeringobjects, removed with repadmin /removelingeringobjects. Prevented by decommissioning DCs before they go offline for more than 60 days.
What is USN rollback and why does it cause active directory replication not working?
USN rollback occurs when a DC VM is restored from a hypervisor snapshot. The DC returns with an older Update Sequence Number. Partner DCs detect the inconsistency, log Event ID 2095, and stop replicating with the affected DC. The only supported fix is demoting the DC and repromoting it from scratch — not repairable with repadmin commands.
Does healthy AD replication mean SYSVOL is also healthy?
No. AD replication and SYSVOL replication are separate. AD replication carries AD objects; SYSVOL replication (DFSR) carries GPO files and logon scripts. repadmin /replsummary shows nothing about DFSR. Run dfsrdiag ReplicationState separately to confirm SYSVOL is replicating correctly.
External References
Microsoft Learn documentation used as primary reference for this guide:
- Diagnose Active Directory replication failures — Microsoft Learn troubleshooting reference
- Repadmin command reference — complete syntax for all repadmin flags
- Lingering object troubleshooting and removal — Microsoft Learn lingering object cleanup guide
Final Thoughts
Most active directory replication not working incidents resolve at DNS or time skew. These two root causes account for the majority of failures, and both can be diagnosed and fixed without touching AD structure or running recovery procedures. Start there before working through the error matrix.
Lingering objects require cleanup but are operationally safe to remove once identified. USN rollback is the only scenario that demands DC demotion — and the only one where attempting to repair in place causes further damage.
Replication is the nervous system of Active Directory. The diagnostic workflow above works the same on a two-DC homelab as it does on a twenty-DC enterprise. The error codes don’t change. The commands don’t change. What changes is the blast radius when something goes wrong and the urgency with which the incident gets treated.
For environments running more than two DCs, alerting on Event ID 1865 and repadmin failure counts before they accumulate is significantly cheaper than diagnosing a replication failure that’s been running for 48 hours.
Active Directory Series
14 articles — Windows Server 2025 · Forest & Domain · FSMO · GPO · Replication · DNS