
Kerberos authentication requires every machine in your domain to agree on the time within five minutes. Cross that threshold — one machine drifts, a snapshot restores an old clock, or the PDC Emulator loses its NTP source — and authentication tickets get rejected, logons fail, replication breaks, and GPO stops applying. Active directory time synchronization is not a background service you configure once. It is a security enforcement mechanism that breaks the domain when it fails.
This guide covers active directory time synchronization as a troubleshooting and recovery problem: W32Time Event 29, “Local CMOS Clock” on a DC, a Kerberos KRB_AP_ERR_SKEW, virtual DC drift after a snapshot restore, and domain-wide drift recovery. Configuration reference is included, but it exists to support the fix path — not as the main story.
- The forest-root PDC Emulator must sync from external NTP (
Type=NTP,Reliable=Yes). Every other DC usesNT5DSand follows the domain hierarchy. Configuring manual peers on non-PDCe DCs creates conflicting time sources. - If the PDCe is a VM, disable hypervisor time synchronization (Hyper-V Integration Services, VMware Tools, Proxmox RTC). This is the most common cause of persistent domain time drift in homelab and SMB environments.
- W32Time Events 38 → 47 → 29 are a cascade, not independent problems. Start with the PDCe upstream source and UDP 123 access, not with member servers.
- “Local CMOS Clock” on a DC means it has no valid time source. On the PDCe, configure external NTP. On any other DC, return it to
NT5DS. - KRB_AP_ERR_SKEW / Event 4769 code 0x25 means clock skew. Check the domain controller time first, not SPNs.
- A severely wrong DC may not auto-correct —
MaxPosPhaseCorrectionlimits large jumps to 48 hours by default. Manual clock correction is required first.
Why Time Breaks Active Directory
Kerberos uses timestamps as part of its replay-attack protection. Every authentication request includes a timestamp, and the KDC verifies it against its own clock. If the difference exceeds the Maximum tolerance for computer clock synchronization policy — default five minutes, configured at Computer Configuration > Policies > Windows Settings > Security Settings > Account Policies > Kerberos Policy — the ticket is rejected with KRB_AP_ERR_SKEW. This is the core reason active directory time synchronization matters: it is not a housekeeping task, it is a Kerberos dependency.
The downstream effects go beyond logon failures. Replication between domain controllers uses Kerberos for authentication — skew causes replication access denied errors and USN conflicts. Group Policy processing requires an authenticated DC connection. Certificate validation compares timestamps. Log correlation across DCs becomes unreliable. Time is structural, not decorative.
The AD Time Hierarchy
Active directory time synchronization follows a defined authority chain. The forest-root PDC Emulator is at the top — it syncs from an external NTP source and is marked reliable. All other DCs in the domain sync from the PDC Emulator using the domain hierarchy (NT5DS). Domain members — servers, workstations — sync from any available DC in their site. This hierarchy is automatic once it is configured correctly.
The stratum level matters for reference. External NTP sources such as pool.ntp.org operate at Stratum 1 or 2. The forest-root PDCe becomes Stratum 2 or 3. Other DCs are one step below. Domain members sit below that. Windows does not display stratum directly, but w32tm /query /status shows it.
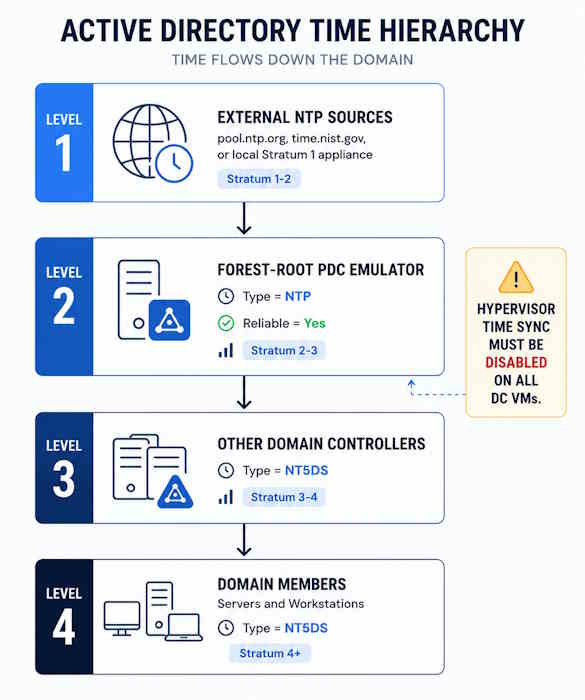
Two configurations break this hierarchy immediately: configuring non-PDCe DCs to use external NTP directly (creates competing time sources), and leaving hypervisor time synchronization enabled on virtual DCs (overrides W32Time with host clock).
First Response: Scope the Problem
Before running any fix, determine whether one machine is wrong or the whole domain is wrong. These are different problems with different starting points.
- Check each DC current time:
net time \\DC01/net time \\DC02. A difference greater than five minutes between DCs is the immediate problem. - Check the PDC Emulator time source:
w32tm /query /sourceon the PDCe. If it showsLocal CMOS Clock, the top of the hierarchy has no valid upstream. - Scan all DCs in the domain at once:
w32tm /monitor /domain:contoso.com. This shows each DC offset, source, and stratum. - If one client or member server is wrong but DCs show consistent time, the problem is local to that machine — run
w32tm /resync /rediscoveron it and check domain connectivity. - If multiple DCs show wrong time, fix the PDCe first. Everything else follows from it.
Find the PDC Emulator and Check Its Configuration
# Find the PDC Emulator
netdom query fsmo
# Check the PDCe time source and status
w32tm /query /source
w32tm /query /status
w32tm /query /configuration
# Full domain-wide DC time scan
w32tm /monitor /domain:contoso.comIn /query /status, look at three fields: Source (should be an NTP hostname, not Local CMOS Clock), Last Successful Sync Time (should be recent), and Stratum (2–4 is normal for a DC; 16 means unsynced).
In /query /configuration, the PDCe should show Type: NTP and NtpServer: <your-peers>. Any other DC should show Type: NT5DS. If a non-PDCe DC shows Type: NTP with manual peers, that is a misconfiguration — it creates a competing time source for active directory time synchronization and must be returned to NT5DS.
Configure the Forest-Root PDC Emulator
Run these commands on the PDC Emulator only. Never run this configuration on a non-PDCe DC.
# Configure external NTP peers with client mode flag (0x8)
w32tm /config /syncfromflags:MANUAL /manualpeerlist:"0.pool.ntp.org,0x8 1.pool.ntp.org,0x8" /reliable:YES /update
# Restart the service
net stop w32time && net start w32time
# Force initial resync
w32tm /resync /force
# Verify it took
w32tm /query /source
w32tm /query /statusThe ,0x8 flag forces client mode. Without it, some NTP servers reject Windows requests because Windows defaults to symmetric active mode. The /reliable:YES flag marks this DC as the authoritative time source for the domain — without it, other DCs may not recognize it as the top of the hierarchy.
Use multiple peers for redundancy. If one NTP server is unavailable, Windows selects another from the list. A single peer creates a single point of failure at the top of the entire domain time chain. Microsoft’s documentation on configuring an authoritative time server covers this configuration in detail.
Type=NT5DS. NT5DS is the domain hierarchy sync mode — the PDCe would try to sync from itself or another DC, find no valid upstream, fall back to Local CMOS Clock, and the entire domain active directory time synchronization hierarchy collapses from the top.
To return a non-PDCe DC to the domain hierarchy after accidental misconfiguration:
w32tm /config /syncfromflags:DOMHIER /reliable:NO /update
net stop w32time && net start w32time
w32tm /resync /rediscoverFix “Local CMOS Clock” on a Domain Controller
“Local CMOS Clock” in w32tm /query /source means W32Time has fallen back to the hardware clock because it cannot find a valid time source. This is one of the most common active directory time synchronization problems, and the fix depends on which DC is showing it.
If this is the forest-root PDCe: no external NTP is configured or reachable. Configure external NTP as above, then check that UDP 123 is not blocked outbound from this DC.
If this is another DC: it has lost contact with the PDCe or the domain hierarchy. Check network connectivity to the PDCe, then run w32tm /resync /rediscover. Verify its configuration shows Type: NT5DS. If the PDCe itself is broken, fix the PDCe first.
If this is a member server or workstation: check domain connectivity, Netlogon service status, and whether the machine can reach a DC. Time sync follows domain health — if the machine cannot authenticate to a DC, it cannot sync from one either.
# On the affected machine
w32tm /query /source
w32tm /query /configuration
nltest /dsgetdc:contoso.com
w32tm /resync /rediscoverFix “The Computer Did Not Resync Because No Time Data Was Available”
This error from w32tm /resync is one of the most-searched W32Time messages. It surfaces for several different root causes, so the diagnostic order matters.
- On the affected machine, check source and configuration:
w32tm /query /sourceandw32tm /query /configuration. Confirm the machine is configured to follow the domain hierarchy (Type=NT5DSfor members and non-PDCe DCs). - If this is the PDCe, test whether the external NTP peer is reachable:
w32tm /stripchart /computer:0.pool.ntp.org /samples:5 /dataonly. A0x800705B4error means timeout — UDP 123 is likely blocked or the peer is down. - Check DNS resolution for the NTP peer name:
Resolve-DnsName 0.pool.ntp.org. DNS failure looks exactly like a time failure and is a common cause of active directory time synchronization errors. - If peers are reachable but sync still fails, try
w32tm /resync /rediscoverbefore anything else. This forces peer rediscovery without resetting configuration. - If the error persists, the W32Time service registration may be corrupt. Re-register it:
net stop w32time
w32tm /unregister
w32tm /register
net start w32time
w32tm /resync /rediscover
Note:/unregister+/registerresets configuration to defaults. If you have non-default settings, back up current config first withw32tm /query /configuration. - Verify with
w32tm /query /status. Look for a valid Source and a recent Last Successful Sync Time.
Fix 0x800705B4 and NTP Timeout Errors
0x800705B4 is a generic timeout — the NTP request was sent but no reply came back. The most common causes are UDP 123 blocked at the firewall, the NTP server not running or rejecting the client, NAT breaking NTP packet timing, or wrong peer flags causing mode mismatch.
# Test the NTP peer directly
w32tm /stripchart /computer:0.pool.ntp.org /samples:5 /dataonly
# If timeout, test a different peer
w32tm /stripchart /computer:time.windows.com /samples:5 /dataonly
# Verify UDP 123 with PowerShell
Test-NetConnection -ComputerName 0.pool.ntp.org -Port 123If stripchart shows timeouts on all peers, the firewall is blocking UDP 123 outbound from the DC. Check firewall rules on the DC itself (Windows Firewall) and on any perimeter firewall. Some environments block UDP 123 outbound from servers by default.
If the peer responds to stripchart but Windows still will not sync, check the manualpeerlist flags. The ,0x8 (client mode) flag is required for many public NTP servers. Without it, Windows uses symmetric active mode and some servers refuse the request.
W32Time Event ID Reference
The 38 → 47 → 29 sequence is the most common active directory time synchronization event cascade. Events 38 and 47 indicate a peer is failing; Event 29 means no source is accessible at all. Always fix the peer source before anything else when you see this sequence in Event Viewer.
| Event ID | Severity | Meaning | What to check |
|---|---|---|---|
| 12 | Warning | PDCe is configured as a client — root of the hierarchy has no valid upstream. Expected on forest-root PDCe only if external NTP is intentionally not configured. | Is this the forest-root PDCe? Configure external/manual NTP and set Reliable=Yes. |
| 24 | Warning | No valid response from a DC after repeated attempts; DC discarded as time source. | DC reachability, UDP 123, domain hierarchy config. |
| 29 | Error | NtpClient has no accessible source. End of the 38→47→29 cascade. No resync for 15+ minutes. | Manual peers, firewall UDP 123, NTP flags, DNS resolution for peer names. |
| 35 | Info | Time service is now synchronizing successfully. | Use as success confirmation after fixes. |
| 36 | Warning | Time service has not synchronized for an extended period. | Upstream availability, PDCe config. Normal on forest-root PDCe if no external source exists — abnormal on any other machine. |
| 37 | Info | Valid time data is being received from a peer. | Use as success confirmation. |
| 38 | Error/Info | NtpClient cannot reach or validate time from a configured peer. Start of the cascade. | Peer reachability, UDP 123, manualpeerlist flags. |
| 47 | Warning | No valid response after 8 attempts; peer discarded. Middle of the cascade. | UDP 123, peer mode flag (,0x8), NTP service on the peer. |
| 50 | Warning | Large time difference detected and corrected. Real drift occurred. | VM drift, host clock, hypervisor time sync, MaxPosPhaseCorrection limits. |
| 129 | Warning | NtpClient could not set a domain peer or discover usable time data. Linked to “no time data was available” errors. | Domain hierarchy, PDCe health, UDP 123. Run w32tm /resync /rediscover. |
| 134 | Warning | DNS resolution failure for NTP peer name. Time failure caused by DNS, not NTP. | DNS resolver config, Resolve-DnsName <peer>, switch to IP if name resolution is broken. |
| 142 | Warning | DC stopped advertising as a time source. More serious on a DC than on a member server — means the DC may no longer be usable for active directory time synchronization by domain members. | Local clock sync status, W32Time provider state, dcdiag /test:Advertising /v. |
Kerberos Errors Caused by Clock Skew
Kerberos authentication failures caused by time skew are frequently misdiagnosed as SPN problems, password issues, or network errors. Time skew is the correct first check whenever Kerberos fails with an error code that maps to clock-related conditions.
| Error / Event | Meaning | First check |
|---|---|---|
KRB_AP_ERR_SKEW |
Clock skew exceeds Kerberos tolerance. The ticket was rejected because the timestamp difference is too large. | w32tm /query /status on client and DC. Compare with net time \\DCname. |
| Event 4769, Failure Code 0x25 | Kerberos service ticket request failed — clock skew. Distinct from 0x20 (expired ticket) which is common and often low value. When you see 0x25 in the Security log, active directory time synchronization is broken. | Check DC and client time. Do not start with SPNs until skew is ruled out. |
| “Clock skew too great” | Platform-agnostic string — same root cause surfacing on Linux, Java, FortiGate, NAS, or backup appliances integrated with AD Kerberos. | Compare the appliance clock against the DC it uses for authentication. The appliance should sync from the domain time hierarchy or from the same NTP source. |
| “There are currently no logon servers available” | Can be DNS, time, DC health, or secure channel. Time skew is one of the three most common causes. | Check DNS first (Active Directory DNS problems), then time skew, then DC health with dcdiag /test:Advertising. |
krb_error 37 / KRB5KRB_AP_ERR_SKEW |
Non-Windows Kerberos error strings for the same 0x25 condition. | Same as KRB_AP_ERR_SKEW — compare appliance or Linux service clock to the DC. |
If an appliance — NAS, backup product, Linux service, FortiGate — reports KRB_AP_ERR_SKEW, start by comparing the appliance clock to the DC it uses for Kerberos. Do not start with SPNs. SPN errors produce a different error code (KRB_AP_ERR_MODIFIED). Clock skew and SPN problems are not the same failure.
Domain Controller Not Advertising as a Time Server
dcdiag /test:Advertising /v
w32tm /query /status
w32tm /query /source
nltest /dsgetdc:contoso.comdcdiag /test:Advertising checks whether the DC is advertising itself as usable. A failure here often correlates with Event 142 — the DC stopped announcing itself as a time source because its local clock is not synchronized. Fix the underlying active directory time synchronization issue first. Once W32Time syncs successfully, the DC resumes advertising and Event 35 or 37 confirms the recovery.
Virtual Domain Controllers: Hyper-V, VMware, and Proxmox/KVM
Virtual DCs are the most common source of persistent domain time drift in homelab and SMB environments. Hypervisor time synchronization overrides W32Time — the VM clock follows the host instead of the domain hierarchy. The fix is to disable the hypervisor guest time sync feature on every DC VM.
Hyper-V and VMICTimeProvider
Hyper-V injects a time provider called VMICTimeProvider into the guest. When enabled, it can override W32Time and sync the guest to the Hyper-V host clock. For domain controllers, the domain hierarchy must remain authoritative for active directory time synchronization.
# Check VMICTimeProvider status from inside the guest
reg query HKLM\SYSTEM\CurrentControlSet\Services\W32Time\TimeProviders\VMICTimeProvider
# Check Integration Services state from the Hyper-V host
Get-VMIntegrationService -VMName "DC01" | Where-Object {$_.Name -eq "Time Synchronization"}
# Disable Time Synchronization from the Hyper-V host
Disable-VMIntegrationService -VMName "DC01" -Name "Time Synchronization"The loop to avoid: a virtual DC syncs from the Hyper-V host. The host is itself a domain member and syncs from that DC. Both machines end up following each other, drifting together, and neither corrects the other.
| VM role | Hyper-V Time Sync | W32Time source |
|---|---|---|
| Forest-root PDCe | Disable | External NTP (manual peers, Type=NTP, Reliable=Yes) |
| Other DCs | Disable | Domain hierarchy (NT5DS) |
| Member server | Usually OK if host time is correct | Domain hierarchy (NT5DS) |
VMware ESXi and the One-Off Synchronization Problem
VMware Tools has two time synchronization mechanisms: periodic sync (runs continuously) and one-off sync (runs during lifecycle events — vMotion, snapshot consolidation, resume from suspended state). Disabling the visible checkbox in VM settings disables periodic sync but may leave one-off sync active.
Per Broadcom KB 432522, VMware Tools can still perform one-off time corrections during VM lifecycle events even when periodic timesync shows as disabled. For domain controllers, verify both mechanisms. Keep the ESXi host clock accurate even when guests follow the AD hierarchy — if the host drifts and triggers a one-off correction, the guest DC clock changes unpredictably and active directory time synchronization breaks.
# Verify W32Time source after a migration or resume event
w32tm /query /source
w32tm /query /statusProxmox and KVM: RTC localtime vs UTC
Windows traditionally expects the hardware RTC (Real-Time Clock) to store local time. Linux/KVM environments default to UTC. When a Windows DC VM runs on Proxmox, this mismatch creates large apparent time jumps after a shutdown/start cycle — the VM reads a UTC RTC value as local time and applies a timezone offset on top, producing a clock error equal to the UTC offset of the machine configured timezone.
# Check if RealTimeIsUniversal is set in the Windows guest
reg query HKLM\SYSTEM\CurrentControlSet\Control\TimeZoneInformation /v RealTimeIsUniversal
# After VM start, verify time is correct before allowing domain operations
w32tm /query /status
w32tm /query /sourceIn Proxmox VM settings, the “Use local time for RTC” option controls whether the hypervisor exposes local or UTC time to the guest. What matters is that the Windows guest and the Proxmox setting agree. Test this in a non-production VM before changing production DCs, and force a resync after any change: w32tm /resync /force.
Recovering From Domain-Wide Time Drift
When multiple DCs have wrong time — after a snapshot restore, a hypervisor host failure, or a prolonged NTP outage — fix in order. DCs must not all be corrected simultaneously. Correct the PDCe first, let it propagate, then validate downstream. This is the most operationally critical active directory time synchronization procedure.
- Stop before touching clocks: if the drift is severe (hours or days), moving clocks backward can invalidate existing Kerberos tickets and cause authentication failures during the correction window. Plan for a maintenance window if possible.
- Identify the PDC Emulator:
netdom query fsmo. - On the PDCe, check whether hypervisor time sync is interfering. If it is a VM, disable hypervisor time sync before correcting the clock.
- Correct the PDCe clock first. If the offset is within a few minutes,
w32tm /resync /forceis enough. If the offset is large (hours), see the MaxPosPhaseCorrection section below — you may need to set the clock manually withSet-Datebefore W32Time will accept the correction. - Configure external NTP if not already done:
w32tm /config /syncfromflags:MANUAL /manualpeerlist:"0.pool.ntp.org,0x8 1.pool.ntp.org,0x8" /reliable:YES /update, then restart W32Time and resync. - Verify the PDCe is now at correct time:
w32tm /query /status. Confirm Source is external NTP and stratum is 2–3. - On each other DC:
w32tm /resync /rediscover. Do not manually set time on non-PDCe DCs — let them pull from the corrected PDCe. - On member machines:
w32tm /resync /rediscover. Domain members follow their authenticating DC automatically — forcing a resync speeds this up. - Validate domain-wide:
w32tm /monitor /domain:contoso.com. All DCs should show offsets within a few seconds and sources pointing to the PDCe hierarchy.
Why a Domain Controller Will Not Correct a Huge Time Offset
Windows restricts how large a time jump W32Time will accept automatically. Domain controllers have a MaxPosPhaseCorrection (maximum forward correction) and MaxNegPhaseCorrection (maximum backward correction), both defaulting to 48 hours (172800 seconds) on Windows Server 2008 R2 and later. Member servers default to 0xFFFFFFFF (unlimited).
If a DC clock is wrong by more than 48 hours — after a prolonged outage, a corrupted CMOS, or a hypervisor failure — W32Time will not auto-correct it. The service accepts the NTP data, determines the required jump exceeds the phase correction limit, and does nothing. The clock stays wrong. This is a frequent source of confusion when active directory time synchronization appears healthy on the NTP side but the DC clock stays incorrect.
The fix is to correct the clock manually first, then let W32Time take over:
# Check current MaxPosPhaseCorrection setting (decimal seconds, 172800 = 48 hours)
reg query HKLM\SYSTEM\CurrentControlSet\Services\W32Time\Config /v MaxPosPhaseCorrection
reg query HKLM\SYSTEM\CurrentControlSet\Services\W32Time\Config /v MaxNegPhaseCorrection
# Manually set the DC clock (run as Administrator)
Set-Date -Date "2026-06-14 10:30:00"
# Then let W32Time resync from the correct source
w32tm /resync /force
w32tm /query /statusDo not permanently set MaxPosPhaseCorrection or MaxNegPhaseCorrection to unlimited on domain controllers. The 48-hour default is intentional — it prevents a corrupt NTP source from moving a DC clock by an arbitrary amount. Manual correction for exceptional situations is the right path, not permanently widening the safety limit.
After Moving the PDC Emulator Role, Update Time Configuration
When the PDC Emulator FSMO role is transferred or seized, the time configuration does not follow automatically. The new PDCe is still configured as a standard DC (Type=NT5DS), and the old PDCe may remain marked reliable with manual peers configured. Left uncorrected, active directory time synchronization breaks at the top of the hierarchy within hours.
# Identify the current PDCe after role move
netdom query fsmo
# On the NEW PDCe: configure as forest-root time authority
w32tm /config /syncfromflags:MANUAL /manualpeerlist:"0.pool.ntp.org,0x8 1.pool.ntp.org,0x8" /reliable:YES /update
net stop w32time && net start w32time
w32tm /resync /force
# On the OLD PDCe: return to domain hierarchy
w32tm /config /syncfromflags:DOMHIER /reliable:NO /update
net stop w32time && net start w32time
w32tm /resync /rediscover
# Verify domain-wide
w32tm /monitor /domain:contoso.comThis step is easy to skip after a role seizure during an outage. Add it to the FSMO seizure runbook. See FSMO roles in Active Directory for the full role transfer and seizure procedures.
Secure Time Seeding and Windows Server 2025
Secure Time Seeding (STS) is a feature that uses SSL/TLS certificate timestamps from HTTPS connections to periodically correct the clock. It is enabled by default in Windows Server 2016, 2019, and 2022. In Windows Server 2025, Microsoft disabled STS by default after customer reports of unexpected large time jumps in certain environments.
STS is not the routine cause of active directory time synchronization drift. It is a rare but serious cause of unexplained, large, one-time time jumps — the kind where the clock moves by hours or days with no W32Time event pointing to it directly. Microsoft’s guidance on Secure Time Seeding recommendations advises evaluating STS on domain controllers and VM hosts specifically.
# Disable STS (do this intentionally and document it)
reg add HKLM\SYSTEM\CurrentControlSet\Services\W32Time\Config /v UtilizeSslTimeData /t REG_DWORD /d 0 /f
net stop w32time && net start w32time
# Confirm the setting
reg query HKLM\SYSTEM\CurrentControlSet\Services\W32Time\Config /v UtilizeSslTimeDataOn Windows Server 2025, STS is disabled by default and this step is not required. On Server 2022 and earlier DCs, consider disabling STS if you see unexplained time jumps that do not correlate with NTP source changes or hypervisor events.
Kerberos RC4/AES Hardening: Related, Not the Same Problem
Windows updates from April 14, 2026 (KB5073381) change the Kerberos KDC default for DefaultDomainSupportedEncTypes, moving toward AES-SHA1 only for accounts without an explicitly configured encryption type attribute. This affects authentication behavior but is distinct from clock skew — the two problems surface similar symptoms but require completely different fixes.
The connection: both time skew and Kerberos encryption changes can produce authentication failures after an update. If Kerberos auth is failing and active directory time synchronization checks out clean, check whether the RC4 hardening rollout is the cause — particularly for service accounts, legacy applications, or non-Windows systems without msDS-SupportedEncryptionTypes configured.
Validation Checklist
- Check PDCe source is external NTP, not Local CMOS Clock:
w32tm /query /sourceon the PDCe. - Confirm PDCe stratum:
w32tm /query /status— stratum should be 2 or 3, not 16 (unsynced). - Scan all DCs:
w32tm /monitor /domain:contoso.com— all DCs should show time within a few seconds of the PDCe, sources pointing to the domain hierarchy. - Confirm no DC shows Local CMOS Clock as source.
- Check Event Viewer on each DC: Applications and Services Logs → Microsoft → Windows → Time-Service. Confirm Events 35 or 37 (sync success), no Events 29, 38, or 142.
- Run
dcdiag /test:Advertising /von each DC — confirm the DC is advertising as a time server. - On a domain member or workstation:
w32tm /resync /rediscover, then confirm time matches the DCs withnet time \\DC01. - If Kerberos failures were occurring, verify they are resolved by attempting authentication to a domain resource from the affected machine.
Prevention
Most active directory time synchronization failures are preventable with two standing practices: keep hypervisor time sync disabled on all DC VMs, and configure at least two external NTP peers on the PDCe. The rest of the hierarchy follows automatically.
For environments where the PDCe cannot reach public NTP — air-gapped networks, strict outbound firewall rules — a hardware Stratum-1 NTP appliance eliminates the public NTP dependency. A Raspberry Pi with a GPS HAT is a practical homelab option for under $50; commercial GPS NTP appliances are available for SMB environments where the hardware cost is justified by uptime requirements.
Add active directory time synchronization validation to the DC post-install checklist. See Active Directory post-install checklist for the full build-out sequence. When the PDCe FSMO role is moved, update time configuration on both the new and old PDCe immediately — it is a step that gets skipped in the stress of a failover and causes problems hours later. The full W32Time tools and settings reference is documented by Microsoft in their Windows Time Service tools and settings guide.
Frequently Asked Questions
Why does my domain controller show “Local CMOS Clock” as the time source?
W32Time cannot find a valid upstream time source and has fallen back to the hardware clock. On the forest-root PDCe, this means external NTP is not configured or UDP 123 is blocked. On any other DC, it means it has lost contact with the domain hierarchy. This is one of the most visible signs of active directory time synchronization failure at the top of the hierarchy.
Should the PDC Emulator use NT5DS or NTP?
NTP, with external manual peers. The forest-root PDCe must use Type=NTP with /reliable:YES. NT5DS is the domain hierarchy mode — if the PDCe uses it, it tries to sync from itself or another DC, finds no valid source, and falls back to Local CMOS Clock. Every other DC should use NT5DS.
Why does w32tm /resync say “The computer did not resync because no time data was available”?
Usually one of: no reachable upstream source (PDCe misconfigured or UDP 123 blocked), broken W32Time service registration (fix with /unregister + /register), or a domain member that cannot find the PDCe. Run w32tm /query /source and w32tm /query /configuration first to narrow the cause before resetting the service.
What does KRB_AP_ERR_SKEW mean?
Clock skew between the client and the KDC exceeds the Kerberos tolerance (default five minutes). The authentication ticket was rejected because the timestamp difference is too large. Compare the affected machine clock against the DC it authenticates against, then fix the time source through active directory time synchronization — not SPNs.
What is Event 4769 failure code 0x25?
A Kerberos service ticket request failed due to clock skew. Code 0x25 is KRB_AP_ERR_SKEW. It is distinct from 0x20 (expired ticket, common and often benign). When you see 0x25, check active directory time synchronization before investigating SPNs or passwords.
Can VMware Tools change the guest clock even when time sync is disabled?
Yes. Disabling periodic time sync in VMware Tools settings does not necessarily disable one-off synchronization during lifecycle events (vMotion, snapshot consolidation, resume). Per Broadcom KB 432522, the guest clock can still be corrected during these events. For DC VMs, verify both synchronization behaviors and keep the ESXi host time accurate regardless.
Should I disable Hyper-V time synchronization on domain controllers?
Yes. Disable the Time Synchronization integration service on all DC VMs in Hyper-V. Let W32Time and the domain hierarchy manage active directory time synchronization. The risk of leaving it enabled is a loop where the virtual DC follows the Hyper-V host clock and the host is itself a domain member syncing from that DC.
Why will a domain controller not correct a large time difference automatically?
MaxPosPhaseCorrection and MaxNegPhaseCorrection limit automatic clock corrections to 48 hours by default on domain controllers. If the offset exceeds this limit, W32Time will not apply it. Manually set the correct time first with Set-Date, then let W32Time resync from the corrected state.
Should I disable Secure Time Seeding on domain controllers?
On Windows Server 2025, STS is disabled by default — no action needed. On Server 2022 and earlier, consider disabling STS (UtilizeSslTimeData=0) on domain controllers and VM hosts if you experience unexplained large time jumps. STS is not the cause of ordinary active directory time synchronization drift, but it can produce rare, hard-to-diagnose sudden time corrections.
Active Directory Series
14 articles — Windows Server 2025 · Forest & Domain · FSMO · GPO · Replication · DNS